内存一致性模型
Published on 2023-02-13
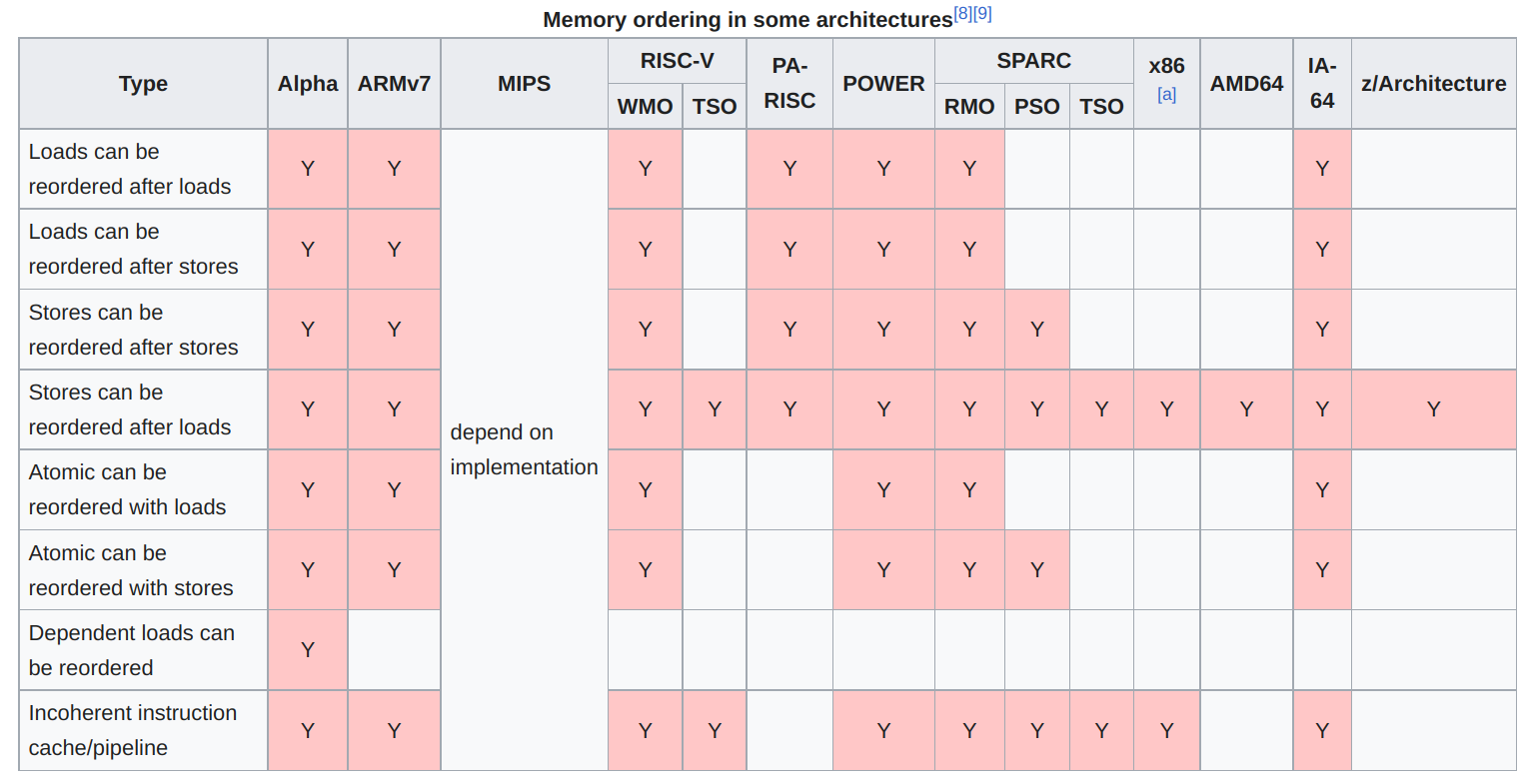
因作者水平有限,本文仅讨论 x86 架构 (TSO) 与 ARMv8 架构 (RMO),以此加深作者本人对硬件并行部分的知识的理解。
TSO (Total Store Ordering)
Can be reordered
- Load Load
- Load Store
- Store Load
- Store Store
如何理解(因无法验证,仅供参考):
CPU 拥有 Store Buffer,当需要 Load 时,如果其它 CPU 没有及时刷出 Store Buffer 则会发生 Store Load 重排序。
PSO (Part Store Ordering)
Can be reordered
- Load Load
- Load Store
- Store Load
- Store Store
如何理解(因无法验证,仅供参考):
Store Load 原因同上
当需要 Store 多个值时,如果发现 Store 的值没有在 Cache 中时,则会延迟写入到内存,此时会发生 Store Store 重排序。
RMO (Relaxed Memory Ordering)
Can be reordered
- Load Load
- Load Store
- Store Load
- Store Store
如何理解(因无法验证,仅供参考):
Store Load 和 Store Store 原因同上
如果发现 Load 的值没有在 Cache 中时,则会从内存中读取,此时会发生 Load Load 或者 Load Store 重排序。
关于 编译器屏障 与 内存屏障
编译器屏障
#include <linux/kernel.h>
void barrier(void); // 指令重排序只在屏障两边生效抑制编译器重排序优化,不影响硬件对指令的执行顺序。
内存屏障
#include <asm/system.h>
void smp_mb(void); // 任何内存访问都将在屏障之前完成
void smp_rmb(void); // 任何内存读访问都将在屏障之前完成(不限制 写访问)
void smp_wmb(void); // 任何内存写访问都将在屏障之前完成(不限制 读访问)抑制硬件级别的重排序优化。